
Best GPUs for Machine Learning Learn more about GPUs and what you specifically need for your machine/deep learning task. Machine learning and deep learning are fields that require intense computational requirements to be able to produce high-performance models and accurate outputs. The GPU you choose to work with has a big impact on your machine […]
Best GPUs for Machine Learning
Learn more about GPUs and what you specifically need for your machine/deep learning task.
Machine learning and deep learning are fields that require intense computational requirements to be able to produce high-performance models and accurate outputs. The GPU you choose to work with has a big impact on your machine learning and deep learning experience.
The training phase in the machine and deep learning process take up the majority of the pipeline. The most valuable phase of the pipeline is when the data scientists, machine learning engineers, and other data professionals can start to work on fine-tuning the model to make it robust. However, these data professionals are often waiting around for the training to be complete, affecting their productivity, time, resources and money.
People are always looking for new ways to improve their current process, speed it up, or automate it purely. The adoption of GPUs into your process will enable you to perform AI computing operations in parallel.
But how do you know which GPU to use? What GPU features should be important to your machine learning task? Will it reduce the overall cost, or increase it? Why do I want to invest in a GPU in the first place?
This blog will go through these questions, taking you to the beginning on what GPUs are, how they work, the best on the market, NVIDIA GPU specs, use cases, and more.
But before we get into the specifics of the GPUs, and the different ones in which we will compare. I am going to introduce you to the basics of artificial intelligence and machine learning, ensuring all the pieces of the puzzle fit nicely. Understanding the basics of machine learning and its process will give you a better grasp of why GPUs are important, and in which stage they will be working their hardest.
What is Machine Learning?
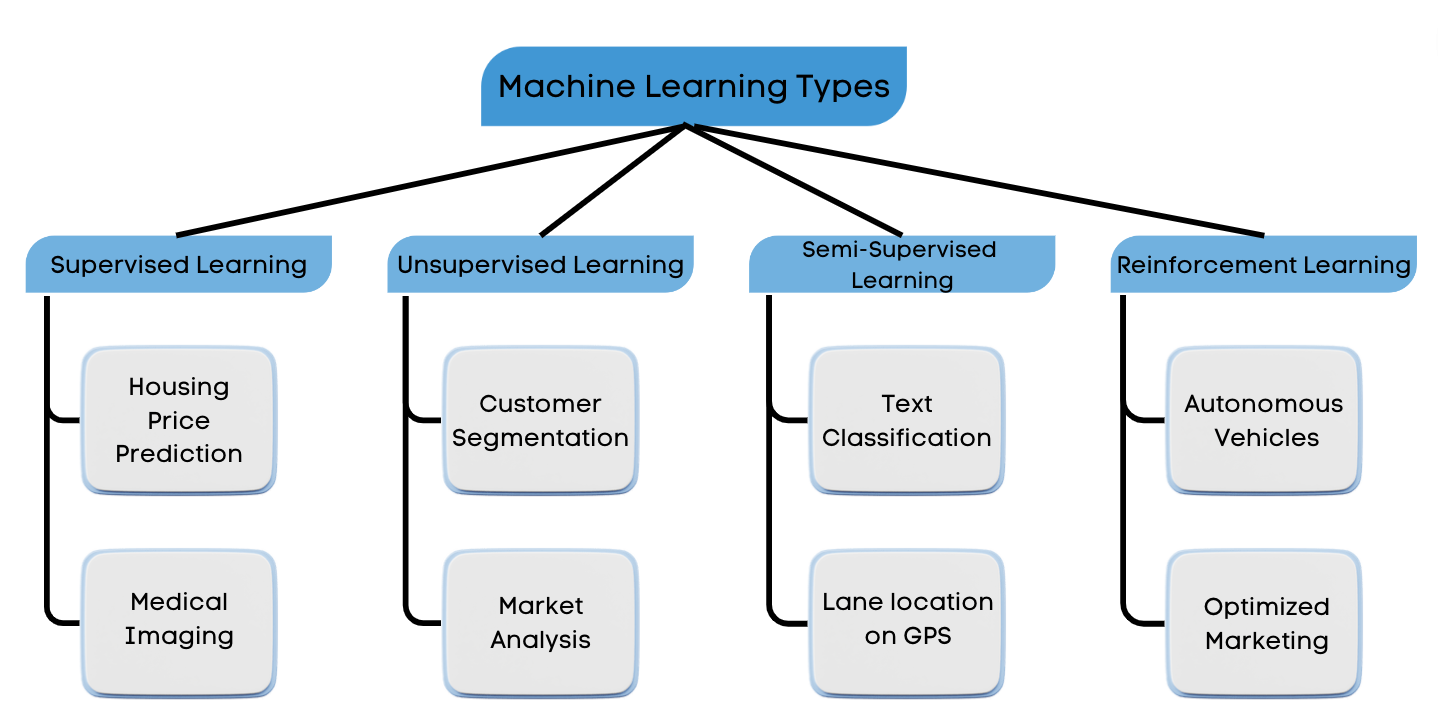
Image by Author
Machine Learning belongs under Artificial Intelligence, the ability of a computer or a computer-controlled robot to perform tasks that are usually done by humans as they require human intelligence.
Machine Learning is the process of allowing models to learn and improve using past experience by exploring the data and identifying patterns with little human intervention. Today we currently work with 4 different types of machine learning: Supervised Learning, Unsupervised Learning, Semi-Supervised Learning and Reinforcement Learning.
Supervised Learning is when an algorithm learns using a labeled dataset and analyzes the training data based on its knowledge learnt using the labeled dataset. These labeled data sets have inputs and expected outputs.
Unsupervised Learning learns on unlabeled data, therefore it requires the model to infer more about the hidden structures of the data in order to produce accurate and reliable outputs.
Semi-supervised learning is a combination of supervised and unsupervised learning. It uses labeled data to make predictions, and unlabeled data to learn the shape of the larger data distribution.
Reinforcement Learning is the training of machine learning models to make a sequence of decisions and focuses on learning the optimal behavior in an environment to obtain the maximum reward. It is considered the science of decision-making.
Machine Learning Process:
So what does the machine learning process look like? Let’s go through the 7 steps of Machine Learning.
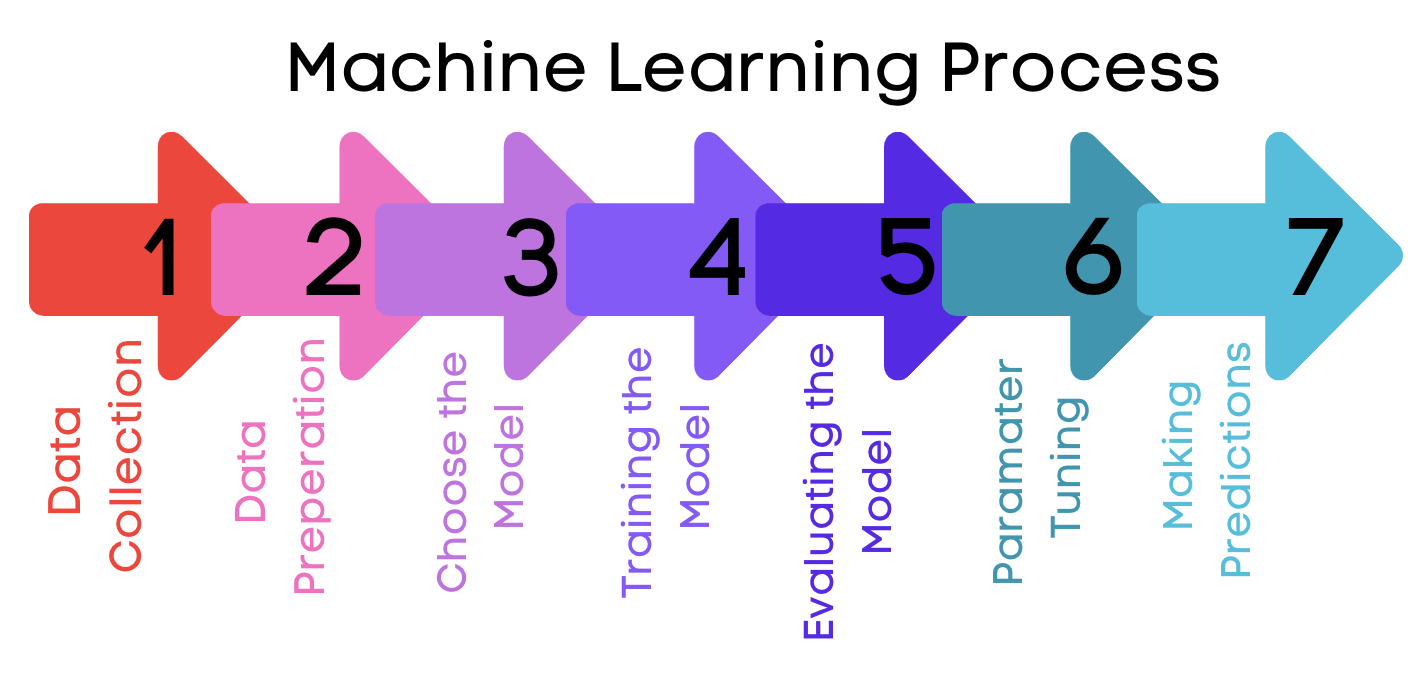
Image by Author
Data Collection
Your data collection is based on the problem or task you are trying to solve. Your data can be pre-collected, or collected by yourself. An important aspect to remember is that the quantity and quality of your data dictate how accurate your model turns out.
Data Preparation
Once you have collected your data, you will need to prepare it in the correct format for it to undergo analysis. This includes cleaning the data, randomizing data, and preparing it for the training phase. You can also create visualizations of the data to give you a better understanding of relevant relationships between variables or class imbalances. You will then split that data into training and evaluation sets, before inputting it into the model.
Choose the Model
Depending on the task at hand, different algorithms are used for different tasks. Therefore, you will need to have an in-depth understanding of what you are trying to solve and what you want your expected output to show.
Training the Model
We all need to learn in order to be proficient in a subject. The same goes for machine learning models – they undergo a training phase which helps them learn about the data, the relationships, and specific variables. The goal of the training phase is for the model to be able to answer a question or make predictions correctly and effectively.
Evaluating the Model
Once the model has made predictions based on the training data, you will need to evaluate its performance. This can be achieved by using performance metrics such as Accuracy, Recall, Precision, and F1- Score. You can also test your model against unseen data to see how effective the training phase works on data the model has not seen before.
Parameter Tuning
At this point, you will understand the limitations of your machine-learning model and will want to improve its performance. Hyperparameter tuning is the process of tuning the model’s parameters for improved performance. The goal is to maximize model performance, whilst being able to minimize a predefined loss function in order to produce better results with fewer errors.
Making Predictions
Your next step would be to test your machine learning model by using test data, where the class labels are known and can give us a better approximation of how the model will perform in the real world.
What are GPUs?
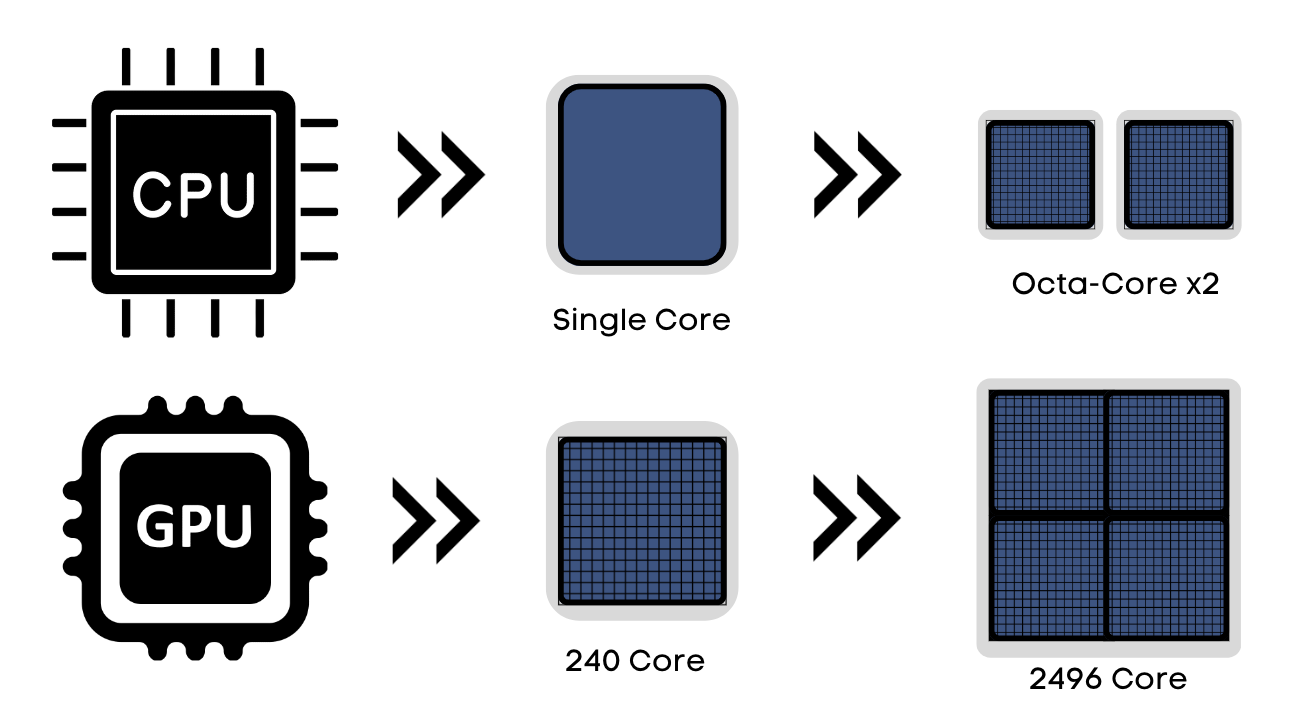
Image by Author
GPU stand for Graphics Processing Unit, and they are built into your device to accelerate graphics and image processing. They are made up of thousands of smaller cores that are designed to work in parallel, allowing them to perform tasks simultaneously and much faster than the CPU.
GPUs are located on graphics cards, which are then plugged into a computer’s motherboard. GPUs are an important element in modern computing, with them constantly evolving to become more powerful to meet the current and future market in computing and technology.
Some newer CPUs have integrated GPUs, allowing them to have specific features and functionality of a graphics card built into the CPU. When it comes to working with machine learning in particular, CPUs unfortunately cannot handle the processing of large data in parallel, the same way GPUs can.
Parallel processing is the method that helps GPUs to function. It is when multiple processors handle separate parts of the same task, allowing the performance of many calculations at the same time.
GPUs have helped to improve a wide range of applications, such as artificial intelligence, scientific computing, graphics and video rendering.
Due to their ability to handle multiple tasks at the same time, GPUs are more energy-efficient than CPUs that can only handle one at a time.
How do GPUs work?
GPUs are made up of thousands of small processing units called cores, where each core can perform a single instruction at a time in a very fast manner. This is how GPUs can deal with computationally intensive tasks and complete them effectively.
As you can imagine, with all the data and tasks GPUs process within a few seconds, they require a large amount of memory to store data and other information that they need to process. Due to the type of tasks that GPUs deal with, they will typically have a much faster memory than a CPU in order to access the stored data quickly.
The generic overview of the GPU process starts with Loading the data -> Processing the data -> Dividing and assigning each part to a different core -> Cores working in parallel -> Send the results back to the memory.
Why GPUs are Important for Machine Learning and Deep Learning
Machine learning and deep learning consist of a lot of complex computing tasks, for example, computer vision, natural language processing, training deep neural networks, mathematical modelling, 3D graphics, and more.
Training Phase
When it comes to machine and deep learning, the most intensive phase in the pipeline is the training phase. The training phase is where your machine learning models digest the prepared data and learn more about the data, find patterns, and make predictions. Machine learning and deep learning algorithms are typically trained on very large datasets, in which the model needs to learn every aspect of the data so that it can accurately complete future predictions and tasks.
This will require a lot of computing power, in order to deal with large volumes of datasets that need mathematical calculations performed in a short period of time. With anything in life, practice makes perfect. The same goes for machine learning models, the more training the model goes through, the better it gets at making predictions.
Therefore, as you increase your training data, the training time will increase with your resources being used up – which can all become very expensive. However, with the use of GPUs, you can run machine learning models with massive numbers of parameters, and complex tasks quickly and effectively.
High Performance and Accuracy
In order for these applications to be able to produce high-performing, accurate outputs – it requires a reasonably powerful GPU. CPUs unfortunately don’t have the high processing power, cores, and memory to handle the complex tasks like GPUs do.
By being able to distribute tasks GPU features help focus on tasks and free your CPUs for other tasks, improving compute capabilities. GPU’s high performance and energy efficiency benefits are becoming more popular as technology continues to grow.
GPU Cluster
Computational-intensive tasks can use GPU clusters to work on a single task together. A GPU cluster is a group of GPUs connected and made up of multiple nodes, which contain either one or more GPUs. The nodes are connected to high-speed networks, such as InfiniBand or Ethernet.
A GPU cluster aims to take a task and divide it up into multiple sub-tasks that can be executed on different GPUs parallelly. GPU clusters are much faster than using a single GPU, and that’s why it’s very popular with deep learning training.
AMD vs NVIDIA
Typically you’ve probably heard about AMD GPUs and NVIDIA GPUs. But what’s the difference between the two? And which one is better for machine learning and deep learning tasks?
AMD stands for Advanced Micro Devices and is produced by Radeon Technologies Group. Graphics cards are important in allowing your PC to be able to display videos, pictures, and other graphics. AMDs are popular due to their offering a powerful value based on their price and a user-friendly interface. They are powerful graphic cards, however, they are not considered as powerful as Nvidia GPUs.
AMD and NVIDIA are the most widely used GPUs on the market at the moment, and due to this, they have had a back-and-forth ongoing battle for GPU supremacy. The two offer a wide range of products, at different prices.
Due to AMD being more in the affordable and comfortable range, they benefit and remain highly competitive. However, NVIDIA works with higher-end GPUs which are valued at a price for customers who need to work with specific features and a level of performance, and can simply afford it.
When you’re looking at GPUs that need to work effectively on machine learning and deep learning tasks, you will steer more towards the GPUs with more features and have a higher level of performance. NVIDIA GPUs offer that, making them very popular in the world of artificial intelligence.
Important GPU Specs for NVIDIA Cards
When looking into NVIDIA GPUs for machine learning and deep learning processes, you need to look at the must-need GPU specs. Your tasks will be more computationally intensive, and require more power and storage.
Processing Cores:
Processing cores are responsible for processing all the data that is fed into and out of the GPU. If you are using an AMD GPU, these processing cores are called AMD stream processors.
CUDA cores are solely for NVIDIA GPUs and are the processors that accelerate the execution of parallel computing. They are made up of smaller units called arithmetic logic units (ALUs) and memory access units (MMUs), and it is these units that optimize parallel processing.
The more CUDA cores a GPU has, the more it can perform multiple calculations at the same time, and perform these tasks faster. CUDA cores provide GPUs with the main capabilities why GPUs are very popular for machine learning and deep learning tasks.
CUDA cores can:
- Perform at high speed
- Provide efficient parallel processing
- Be a cost-effective alternative to computationally intensive tasks
CUDA cores specialize in parallel computing, whereas Tensor cores are more specialized processors to work with deep learning and AI workloads. Tensor cores allow for mixed-precision computing, adapting calculations dynamically, and improving and maintaining accuracy.
Memory Bandwidth
When working with machine learning and deep learning models, you will be working with large datasets. In order for your GPU to handle these large amounts of data, it needs memory bandwidth. Memory bandwidth is the amount of data a GPU can read or write from its memory per second. The higher the memory bandwidth, the faster the GPU can process data.
GPU Memory
The data that the GPU can read or write from is stored. GPU memory is the amount of storage space available for the GPU to store data securely. If you are working on models such as large language models, you will need to use a lot of datasets to produce a high-performance machine learning mode. But at the same time, you will also require high GPU memory to store the data.
Use Case 1: Stable Diffusion
To give you a better understanding of GPU applications, let’s talk about stable diffusion.
What is Stable Diffusion?
Stable Diffusion is a type of diffusion model, called Latent Diffusion Model, and is the open-source alternative to DALL-E 2. The latent Diffusion Model is a machine learning model that is designed to learn the underlying structure of a dataset by mapping it to a lower-dimensional latent space. Latent diffusion models are a type of deep generative neural network, which was developed by the CompVis group at LMU Munich and Runway.
Stable diffusion is a text-to-image model, which was released in 2022. The model can generate detailed images based on text descriptions, as well as inpainting, outpainting, and more. The stable diffusion model has been trained on a large dataset of images and texts and has been used to create a wide variety of images.
How does Stable Diffusion Work?
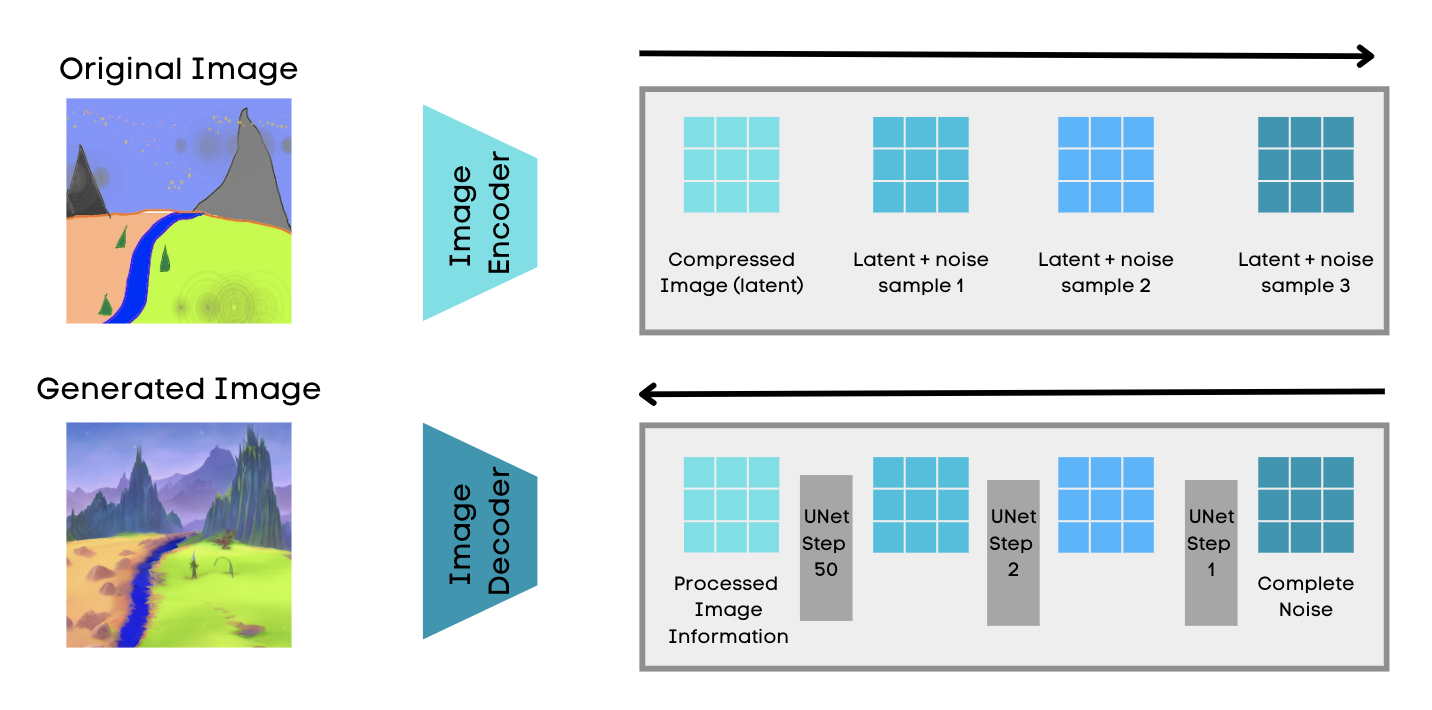
Image by Author
Stable Diffusion starts off by first compressing the image into a latent space, which is a much smaller dimensional space than the actual image space. Stable diffusion is achieved by using a technique called the variational autoencoder, a neural network that has two parts: an encoder and a decoder. The role of the encoder is to compress the image into a lower dimensional representation in the latent space whilst the role of the decoder is to restore the image from the latent space. Although it will be compressed, it still contains all the qualities and information of the actual image.
The diffusion process is when you slowly add or diffuse noise to the compressed latent representation, and generate an image that is just noise. However, the diffusion model goes in the opposite direction and does the reverse process of diffusion. The noise is gradually reduced from the image in a controlled way, so the image slowly appears to look like the original.
This is done using U-Net architecture, a convolution-based neural network that can do image localisation by predicting the image pixel by pixel. This is how stable diffusion generates realistic and very detailed images.
In order for Stable Diffusion to run effectively, you will need:
- 16GB of RAM
- Nvidia graphics card with at least 10GB of VRAM
Real-world applications of Stable Diffusion
Here is a list of real-world applications of Stable Diffusion:
- Art creation, such as photos of real-world objects, real-like paintings, imaginary landscapes, abstract art, and more.
- Product design
- Education
- Entertainment
Use Case 2: Large Language Models
What are Large Language Models?
Large Language Model (LLM) is a currently popular deep-learning algorithm consisting of a neural network, giving the model the ability to read, recognise, summarize, translate, predict and generate text. They are a type of transformer model, a neural network that learns context by tracking relationships in sequential data.
They require to be trained on large amounts of text data to be able to successfully generate accurate outputs. Predicting future words and constructing a sentence allows the model to better understand how humans talk and write and be able to have conversations – just like humans!
You may have heard of the popular ones ChatGPT and Google Bard.
How do Large Language Models work?
Image by Author
As we can assume from its name, Large Language Models (LLMs) need large amounts of data to be trained on. For example, if you’ve had a chance to trial ChatGPT and Google Bard, it’s quite amazing how the applications can answer the majority of your queries, with a few limitations. This is down to the variety of data sources, such as books, articles, websites, and social media that were used as training data for the model.
Large language models are types of transformer models, a neural network that learns context and tracks the relationships in sequential data, for example, words in a sentence. They use mathematical techniques called attention or self-attention, where attention is when a transformer model attends to different parts of another sequence, whereas self-attention is when a transformer model attends to different parts of the same input sequence.
LLMs use unsupervised learning, where the model learns on unlabeled data, more about the hidden structures and the construction of sentences and relationships between the words. Along with LLMs learning context by tracking relationships in sequential data, LLMs can predict the next word in a sentence by analyzing the words that came before it. The unsupervised learning and transformer model features help the LLM to learn more about language, context, grammar, and tone of language.
Looking at GPT-3, it’s a 175 billion-parameter language model that focuses purely on language and has an in-depth understanding of the written and spoken word. That is a lot of data, and a model this large would have required high computational power, high memory bandwidth, and a lot of memory. In order for GPT-3 to be successful, the company stated that:
“The precise architectural parameters for each model are chosen based on computational efficiency and load-balancing in the layout of models across GPUs. All models were trained on NVIDIA V100 GPUs on part of a high-bandwidth cluster provided by Microsoft”
Real-world applications of LLM:
- Chatbots: Powering chatbots such as ChatGPT and Google Bard AI that can have conversations with humans, by answering questions, providing customer service, and generating content.
- Virtual assistants: LLMs are used to power virtual assistants such as Siri and Alexa. They can understand and respond to natural language, as well as handle tasks.
- Translation: You can use LLMs to translate text from one language to another.
- Content generation: LLMs can generate text in different types of content, such as blog posts, product descriptions, poems, songs, and marketing materials.
Different Types of GPUs
So we’ve gone through what machine learning is, what GPUs are and how they work, along with 2 use cases of GPU. Let’s now look into the different types of GPUs.
Nvidia A100 80GB
The Nvidia A100 80GB is a GPU designed for high-performance computing (HPC) and artificial intelligence (AI) applications. It is based on the Nvidia Ampere architecture and delivers up to 20x faster performance than the previous generation GPUs. It is considered a highly valuable tool for researchers and engineers.
Nvidia A100 has been used in deep learning training and machine learning inference such as image classification, scientific computing such as weather forecasting, and creating data visualization for sectors such as scientific data and financial data.
A100 instance
Using the Nvidia A100 GPU, we can create an A100 instance – a virtual machine for compute and storage. You can either have one whole GPU, or you could divide that one GPU up into seven GPU instances with Multi-Instance GPU – where this one of seven partitions is called a GPU slice.
A100 instances are available on Google Cloud Platform, Amazon Web Services, and Microsoft Azure. The price of these instances is based on the number of A100 GPUs used, the memory consumed, and the CPU. GPU instances are ideal for applications that require high-performance computing, for example, training and running deep learning, machine learning, and scientific computing.
Pros and Cons of Nvidia A100
| NVIDIA A100 | |
|---|---|
| Pros | Cons |
| High-Performance Computing – The A100 is a very powerful GPU that can manage a variety of tasks. | Price – The A100 is very expensive. |
| Efficiency – The A100 can handle multiple tasks at the same time at high performance, without consuming a lot of power. | Power Consumption – Due to its high performance, the A100 can consume a lot of power. |
| Variety of Applications – The A100 can be used in different applications, such as deep learning, machine learning, scientific computing, and more. | Scarce – The A100 is very high in demand, therefore it is not always available. |
Nvidia A6000
The Nvidia A6000 is a visual computing GPU based on the NVIDIA Ampere architecture and was curated for creative professionals, scientists, etc who need powerful performance when working with demanding workloads.
The A6000 has 48GB of GDDR6 memory, 10,752 CUDA cores, and 336 Tensor cores. It also has 32GB of NVLink memory bandwidth and 1.5 terabytes per second of memory bandwidth. These features make it a demanding and powerful tool for a lot of professionals to work on real-time ray tracing, artificial intelligence, video editing, 3D rendering, and more.
Pros and Cons
| NVIDIA A6000 | |
|---|---|
| Pros | Cons |
| Powerful – Based on its features such as memory, CUDA cores, Tensor cores and more, the A6000 is a powerful GPU that can deal with demanding tasks quickly. | Price – The A6000 is very expensive. |
| High Memory Bandwidth – The A6000 has 1.5 terabytes per second and 32GB of NVLink memory bandwidth, making it very quick for it to access large data quickly. | Power Consumption – Due to its high performance, the A6000 can consume a lot of power. |
| Variety of Applications – The A6000 can be used in different applications, such as deep learning, machine learning, scientific computing, and more. | Scarce – The A6000 is very high in demand, therefore it is not always available. |
Nvidia A4500
Similar to the A6000, the NVIDIA RTX A4500 is a professional graphics card designed for creative professionals, engineers, etc who need powerful performance for demanding workloads.
It has lower features in comparison with A6000, with RTX A4500 at 20GB of GDDR6 memory, 56 second-generation RT Cores, 224 third-generation Tensor Cores, and 7,168 CUDA® cores. It has 20GB of NVLink memory bandwidth and 9.78 terabytes per second of memory bandwidth.
Pros and Cons
| NVIDIA A4500 | |
|---|---|
| Pros | Cons |
| Affordable – The A4500 is considered a relatively affordable graphics card. | Limited Memory – The A4500 only has 20GB of memory, which can also limit its application and performance. |
| Performance – Based on its price, the A4500 has good performance when and is power-efficient. | No ray tracing and DLSS: The A4500 does not support ray tracing and DLSS, a popular feature in the performance of video games. |
| Variety of Applications – The A4500 can be used in different applications, such as real-time ray tracing, artificial intelligence, video editing, 3D rendering, and more. | |
Nvidia RTX 4090
The Nvidia RTX 4090 is based on the Nvidia Ada Lovelace architecture and is the expected successor of the Nvidia RTX 3090. The Nvidia 4090 features include 16,384 CUDA cores, 24GB of GDDR6X memory, and a boost clock speed of 2.4 GHz. It is also expected to support ray tracing and DLSS.
Its features mean that it is a more powerful graphics card that can handle demanding games and applications.
Pros and Cons
| NVIDIA RTX 4090 | |
|---|---|
| Pros | Cons |
| Performance – Based on its features, the RTX 4090 is very powerful and can handle the most demanding games and applications. | Price – The RTX 4090 is expensive, due to its features. |
| Ray Tracing and DLSS – a feature that was limited in the A4500, is available in RTX 4090. It can improve the performance of games by up to 50% and make them look better. | Power Consumption – The RTX 4090 consumes a lot of power, which could be ineffective. |
| 8K Gaming – The RTX 4090 can handle 8K Gaming, taking the gaming resolution to the next level. | Cooling – Due to the above con, it can generate a lot of heat and may need the cooling system to bring it down. |
| AI Acceleration – Dedicated AI cores in the RTX 4090 can help to improve AI performance. | Scarce – Due to the demand, the RTX 4090 lacks availability. |
Nvidia 3090
The NVIDIA RTX 3090 was released in September 2020 and is based on the NVIDIA Ampere architecture and is the best choice for gamers and professionals who need a powerful graphics card as well as for people who want to future-proof their PC.
It has 24GB of GDDR6X memory, a boost clock speed of 1.7 GHz, reaching a speed of up to 2.5 GHz and 10,496 CUDA cores and 320 Tensor Cores. These features allow it to handle the most demanding games and applications.
Pros and Cons
| NVIDIA RTX 3090 | |
|---|---|
| Pros | Cons |
| Performance – Based on its features, the RTX 3090 is very powerful and can handle the most demanding games and applications. | Price – The RTX 3090 is expensive, due to its features. |
| Ray Tracing and DLSS – available in RTX 3090 and can improve the performance of games by up to 50% and make them look better. | Power Consumption – The RTX 3090 consumes a lot of power, which could be ineffective. This can make a lot of noise too. |
| 4K and 8K Gaming – The RTX 3090 can handle 4K and 8K Gaming, taking the gaming resolution to the next level. | Cooling – Due to the above con, it can generate a lot of heat and may need a cooling system to bring it down. |
| AI Acceleration – Dedicated AI cores in the RTX 3090 can help to improve AI performance. | Scarce – Due to the demand, the RTX 4090 lacks availability. |
Nvidia GPU Benchmark for Stable Diffusion
In order to give you a better understanding of how well these different GPUs work on AI applications, we have created our own benchmarks. To test the performance of the discussed GPUs on Stable Diffusion, we used ‘InvokeAI’, a very popular creative engine used to generate visual media.
Using the SD 2.1 768x model, the denoising diffusion implicit model (DDIM) as a sampler and 50 steps. Using 20 images, we averaged out the speed which is measured in it/s (iterations per second). The higher the iterations per second, the better.
So what did we find?
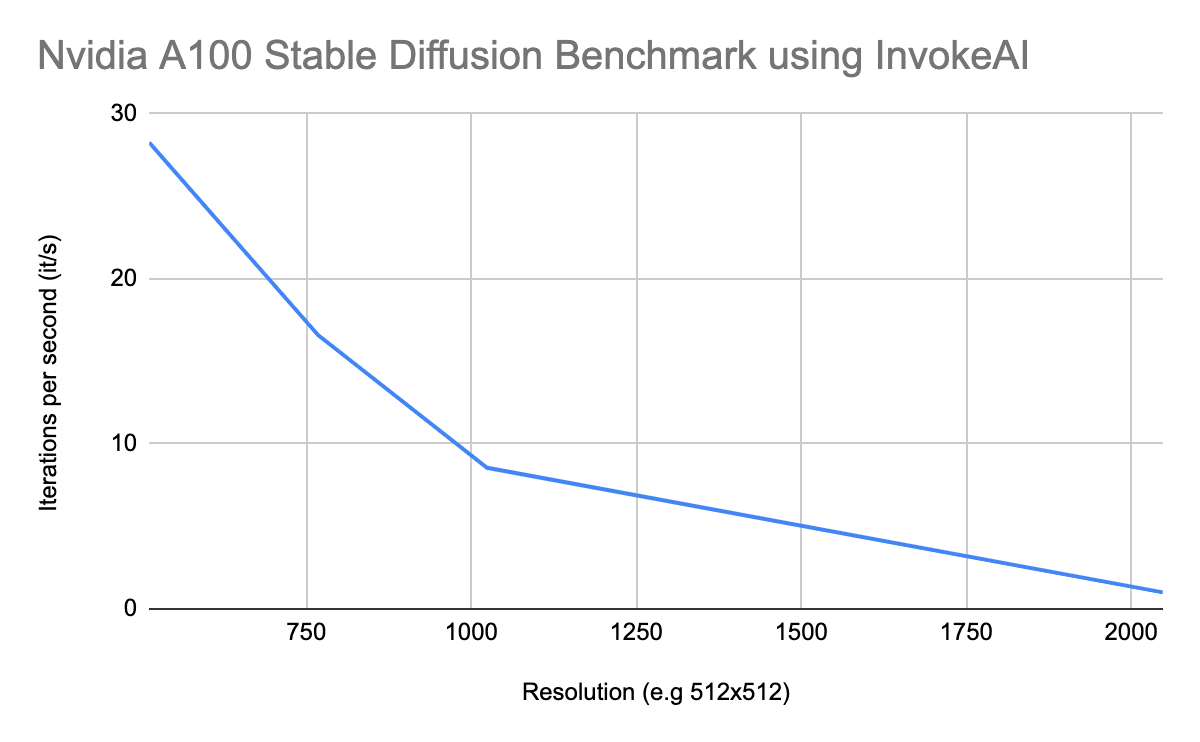
Nvidia A100 Stable Diffusion Benchmark using InvokeAI
| Nvidia A100 Stable Diffusion Benchmark using InvokeAI | |
|---|---|
| Resolution (e.g 512×512) | Iterations per second (it/s) |
| 512 | 28.26 |
| 768 | 16.60 |
| 1024 | 8.55 |
| 2048 | 1.0 |
 Nvidia A6000 Stable Diffusion Benchmark using InvokeAI
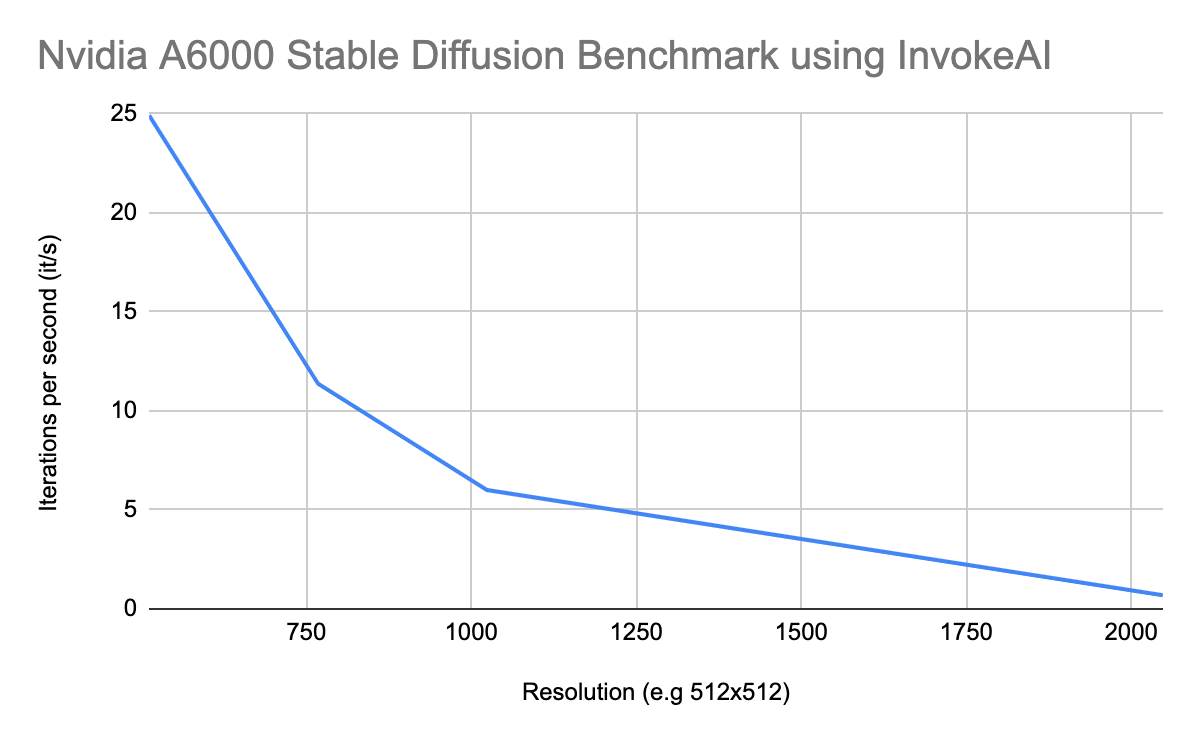
Nvidia A6000 Stable Diffusion Benchmark using InvokeAI
| Nvidia A6000 Stable Diffusion Benchmark using InvokeAI | |
|---|---|
| Resolution (e.g 512×512) | Iterations per second (it/s) |
| 512 | 24.92 |
| 768 | 11.37 |
| 1024 | 6.00 |
| 2048 | 0.69 |
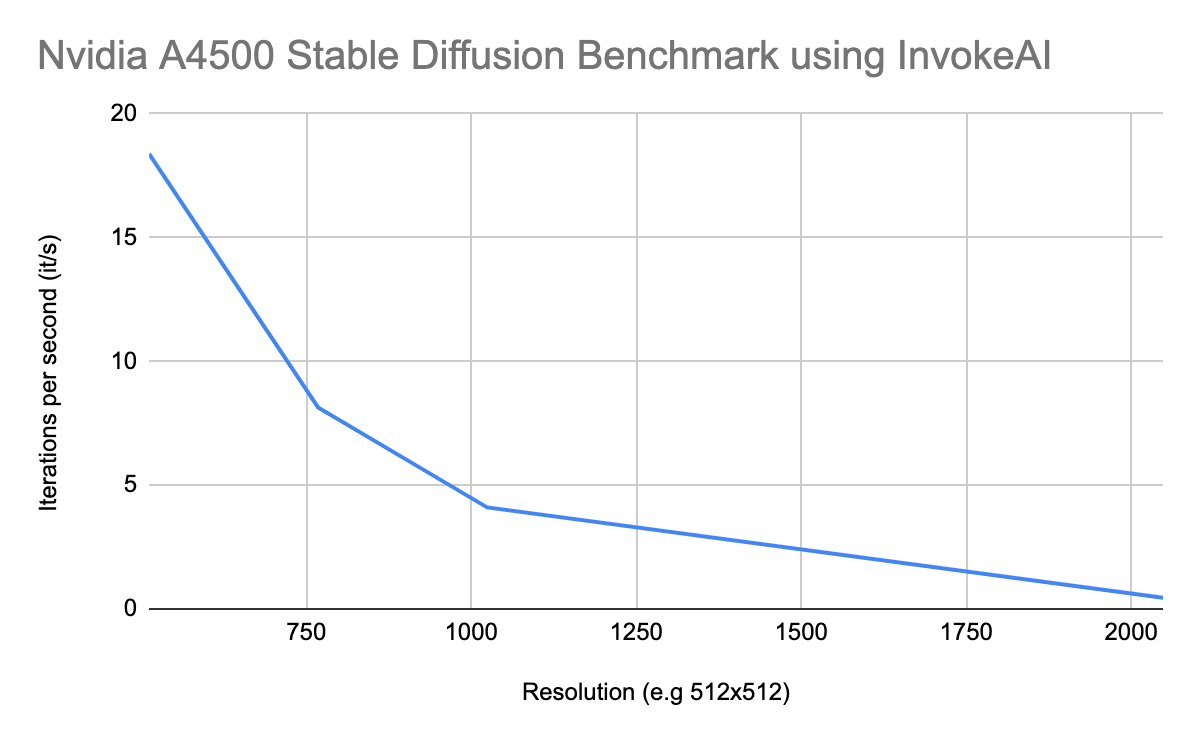
Nvidia A4500 Stable Diffusion Benchmark using InvokeAI
| Nvidia A4500 Stable Diffusion Benchmark using InvokeAI | |
|---|---|
| Resolution (e.g 512×512) | Iterations per second (it/s) |
| 512 | 18.38 |
| 768 | 8.14 |
| 1024 | 4.10 |
| 2048 | 0.45 |
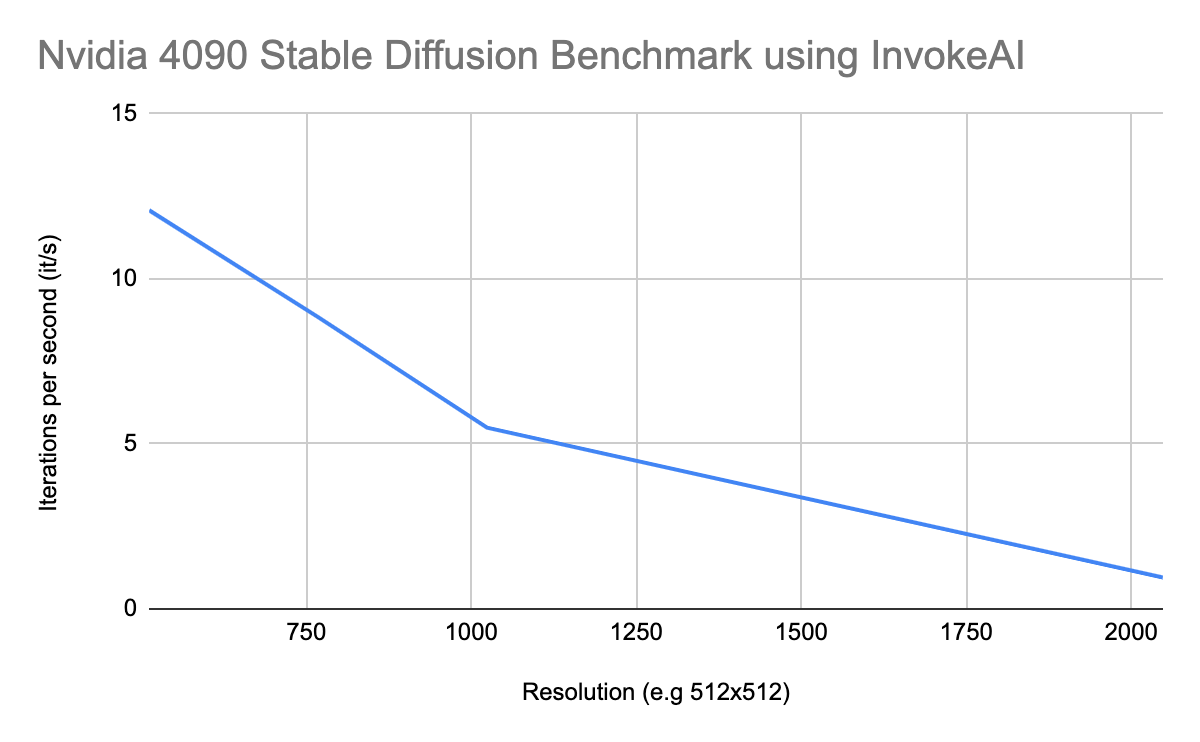
 Nvidia 4090 Stable Diffusion Benchmark using InvokeAI
Nvidia 4090 Stable Diffusion Benchmark using InvokeAI
| Nvidia 4090 Stable Diffusion Benchmark using InvokeAI | |
|---|---|
| Resolution (e.g 512×512) | Iterations per second (it/s) |
| 512 | 12.08 |
| 768 | 8.84 |
| 1024 | 5.49 |
| 2048 | 0.95 |
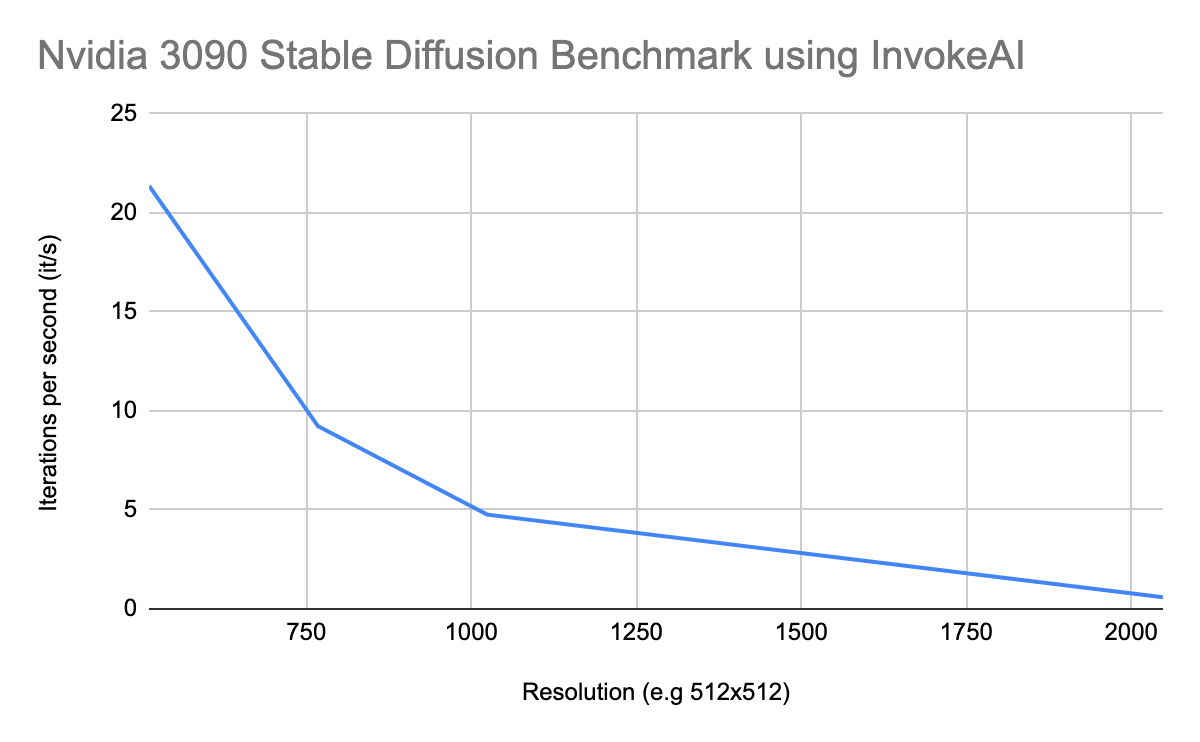
 Nvidia 3090 Stable Diffusion Benchmark using InvokeAI
Nvidia 3090 Stable Diffusion Benchmark using InvokeAI
| Nvidia 3090 Stable Diffusion Benchmark using InvokeAI | |
|---|---|
| Resolution (e.g 512×512) | Iterations per second (it/s) |
| 512 | 21.36 |
| 768 | 9.22 |
| 1024 | 4.76 |
| 2048 | 0.59 |
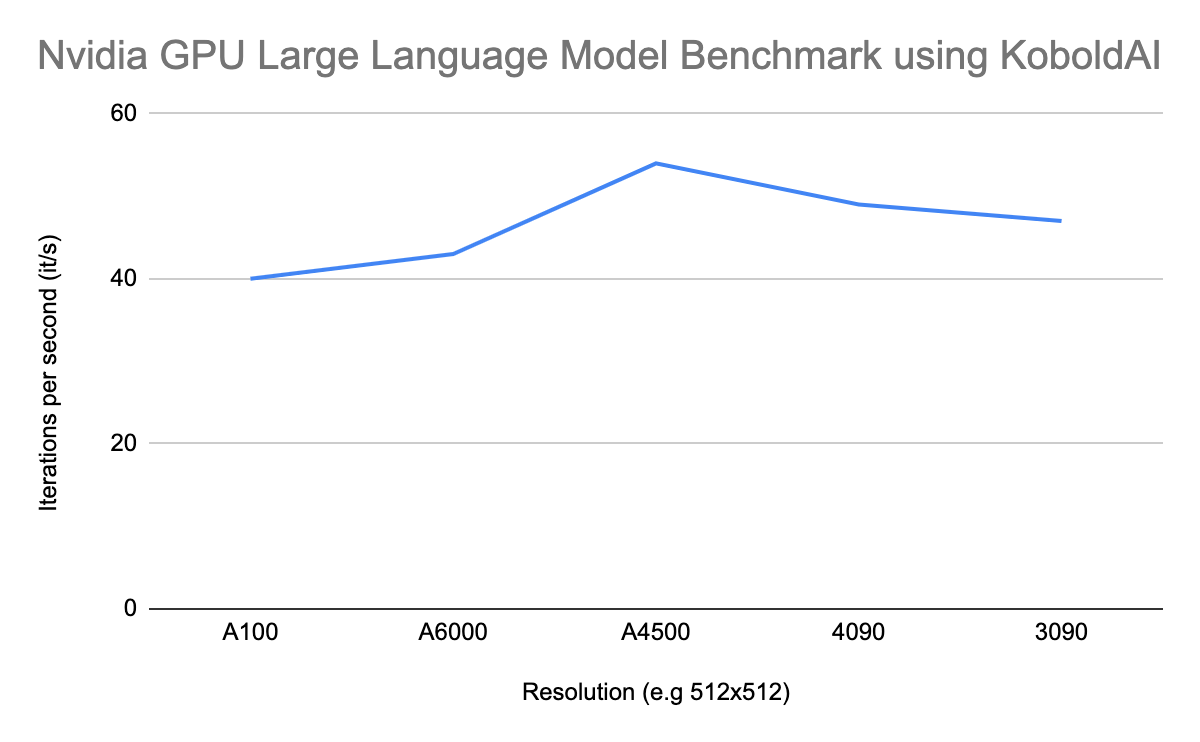
 Nvidia GPU Benchmark for Large Language Models
Nvidia GPU Benchmark for Large Language Models
Large language models are very popular at the moment and they will only continue to grow. You’re hearing a lot about ChatGPT, Bard, and we’re waiting for more to come. To test the performance of the discussed GPUs on Large Language Models, we used ‘KoboldAI’, also known as the gateway to GPT writing. KoboldAI provides AI-assisted writing and has been a very popular tool in helping users create interactive stories or novels.
Using the Untuned XGLM 7.5B model, which is the largest model that fits on all GPUs. The A4500 GPU has the least amount of memory, therefore it created a size limit which we could use.
We set the number of tokens to generate at “512” and prompted the AI application to write a story based on the first line “It was a dark and stormy night”. The faster it took the AI system, the better.
This is what we found:
Nvidia A100 Large Language Model Benchmark using KoboldAI
| Nvidia GPU Large Language Model Benchmark using KoboldAI | |
|---|---|
| GPU | Seconds |
| A100 | 40 |
| A6000 | 43 |
| A4500 | 54 |
| 4090 | 49 |
| 3090 | 47 |
 GPU Comparisons
GPU Comparisons
So now we have a good understanding of these GPUs, their features and what their main purpose is. Let’s compare them all, to get a better understanding of which one to use for Machine Learning.
| GPU | Price | Performance | Power Consumption | Availability |
|---|---|---|---|---|
| Nvidia A100 80GB | $15,999 | Enterprise-level performance | 400 watts | Limited availability |
| Nvidia A6000 | $3,999 | High-end performance for various applications | 300 watts | Good availability |
| Nvidia A4500 | $2,499 | High-end performance for various applications | 200 watts | Good availability |
| Nvidia 4090 | $1,599 | High-end gaming performance | 450 watts | Limited availability |
| Nvidia 3090 | $1,499 | High-end gaming performance | 350 watts | Good availability |
Looking at the table above, we can see that the most expensive GPU on the market is naturally the most powerful one. If you need the best possible performance on the market for applications such as AI, the Nvidia A100 is the best choice.
GPUs for Machine Learning
All the above GPUs that we compared are powerful GPUs that can be used for machine learning. However, there are some key differences that you need to take into consideration when deciding what GPU to use for your machine learning project or application.
Stating the obvious, the A100 80GB is the most powerful GPU specifically designed for machine learning applications. It has the highest machine learning performance and VRAM, making it perfect for training and running large deep learning models and other compute-intensive tasks quickly. But, remember it comes at a price, and there is limited availability.
Moving on to the next. The A6000 is a more general-purpose GPU which you can use for machine learning. Its features are lower than the A1000, but it is the more affordable option that still provides a lot of power for working with machine learning and deep learning applications.
If you’re starting out with GPUs in machine learning, the A4500 is the entry-level GPU you need. It has lower CUDA cores than the A6000, but it can still perform basic machine-learning tasks at a more affordable price.
If you’re looking for gaming GPUs and machine learning, then 4090 and 3090 are the ones for you. They both have higher CUDA cores and VRAM, making them effectively fast on compute-intensive tasks. However, they are not designed specifically for machine learning and have lower performance.
| Specification | Nvidia A100 80GB | Nvidia A6000 | Nvidia A4500 | Nvidia 4090 | Nvidia 3090 |
|---|---|---|---|---|---|
| CUDA cores | 6912 | 10752 | 7168 | 16384 | 10496 |
| VRAM | 80GB | 48GB | 20GB | 24GB | 24GB |
| Memory Bandwidth | 2039 GB/sec | 768GB/sec | 640GB/sec | 1008 GB/sec | 936 GB/sec |
| Power Consumption | 400 watts | 300 watts | 200 watts | 450 watts | 350 watts |
| Price | $15,999 | $3,999 | $2,499 | $1,599 | $1,499 |
How to Decide which GPU to use?
In the ideal world, the Nvidia A100 would be your first choice and that’s that. But there are some factors you need to take into consideration when deciding which GPU to purchase.
- Goal: You want to purchase a GPU? Understanding the context behind your goal, the expectations, limitations, etc will help you plan what you want your end goal to be with purchasing this GPU to be.
- Budget: GPUs can be very expensive, therefore you need to set a budget on how much you’re willing to spend.
- Performance: Depending on your goal, you will need to choose a GPU that matches the performance you envision for your goal. For example, a gamer may need a GPU to handle the newest games and features.
- Power Consumption: Power consumption can be costly and become ineffective. Choosing a GPU that is compatible with your power supply is important.
- Compatibility: All GPUs are not compatible with all computers, therefore you will need to look into the compatibility of the GPU you are interested in.
- Features: Depending on your goal and the reason for your GPU purchase, you may require a GPU that has specific features. For example, gaming features would be the best on 3090 AND 4090.
How to Decide Which GPU to Use for Machine Learning:
When you’re looking at purchasing a GPU, you want to look back at the 7-step machine learning pipeline. When you start a new project, your team will come together and discuss the potential task at hand, what they want to achieve, the overall goal, and how they are going to get there.
In this discussion, you will look into:
- Data: Depending on the problem or task at hand, you will require a certain amount of data. The goal of the project will help you determine how much data is required. Processing large amounts of data requires a GPU with high memory and computing power.
- Algorithms: Depending on which algorithm you choose will help you determine the type of GPU you will need. For example, supervised learning classification tasks will typically require less computational power and memory in comparison to unsupervised learning classification tasks.
- Performance: Ideally you would want your machine learning model to perform very well and as fast as possible. Running complex machine learning models requires a high-power GPU, to ensure high performance.